

TL;DR / Key Takeaways
- NeuralArB‘s neural arbitrage bot has grown x200 in performance capacity.
- Catalyst: massive server-side data storage expansion from <1 TB to 200 TB.
- Prediction accuracy jumped from 72% to 94.7%.
- The bot now monitors 200+ exchanges with 3 TB/sec throughput.
- Risk-adjusted ROI improved from 43.9% to 415.3% over 90 days.
- Continuous learning loop: more data → smarter models → better trades → more data.
Introduction: The Data Imperative in Algorithmic Trading
Data is the new oil in algorithmic trading, but in crypto markets it is better described as both the fuel and the engine. Every spread, liquidity vacuum, order book imbalance, and cross-exchange discrepancy exists inside a fast moving stream of information. Traders who can capture, store, and interpret that stream in real time gain a structural edge. Traders who cannot are left reacting to conditions that have already changed.
That is why the NeuralArB x200 growth milestone matters. This is not just a story about adding more servers or reporting a bigger number. It is the story of how a deliberate expansion in server-side data storage transformed the operating ceiling of our neural arbitrage bot. By scaling from less than 1 TB of storage to a 200 TB cloud-native data lake, NeuralArB unlocked the historical depth, retrieval speed, and model training frequency required for materially higher neural trading efficiency.
In practical terms, more storage means more usable intelligence. A modern neural network trading bot does not only need current prices. It needs years of tick history, full-depth order books, volatility clusters, liquidation cascades, cross-chain bridge activity, sentiment signals, and the context surrounding past market regimes. Without that accumulated data, even strong models remain partially blind. With it, they can learn the difference between a real dislocation and a false edge created by thin liquidity, API lag, or temporary fragmentation.
This is the central thesis of data-driven trading at NeuralArB: the volume and quality of accumulated data directly determine how well an AI system can identify arbitrage opportunities, predict microstructure shifts, and execute with confidence. The neural arbitrage bot becomes smarter not because its architecture exists on paper, but because its architecture is continuously fed with richer, broader, and deeper market evidence. That evidence now spans more than three years of market behavior across bull, bear, and sideways environments.
By expanding our server-side data storage, we enabled our models to detect subtle multi-asset relationships before human traders or traditional bots can act. The result is higher prediction accuracy, faster execution, lower false positives, and significantly better risk-adjusted performance. Accumulated data trading is no longer an optional optimization layer. It is the infrastructure foundation that makes NeuralArB x200 growth possible. In the sections below, we explain exactly how that transition happened and why it changed the economics of AI crypto arbitrage.
What Is NeuralArB?
NeuralArB is an AI-powered crypto arbitrage platform built to identify and exploit price discrepancies across a fragmented global market. At its core, the system is a neural network trading bot designed specifically for high-frequency, multi-venue decision making. Instead of relying on static if then logic, it uses deep learning to interpret market structure, rank opportunity quality, and suppress low-conviction signals before capital is routed.
The model stack combines Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM) networks, and Transformer architectures. CNN layers analyze order books as spatial structures, learning how depth, imbalance, and liquidity density evolve around important price levels. LSTM models capture temporal relationships in the flow of trades and quote updates. Transformer layers provide cross-asset and cross-timeframe context, helping the bot weigh how one market event may affect another venue, token, or chain.
The platform monitors order books, trade ticks, and liquidity pools across 200+ cryptocurrency exchanges and venues. This includes major centralized platforms such as Binance and Coinbase, while also tracking decentralized liquidity sources where pricing inefficiencies can develop for very different reasons. That breadth matters because AI crypto arbitrage depends on seeing the full opportunity surface, not just one narrow slice of it.
At the hardware level, NeuralArB processes real-time data at up to 3 TB/sec through a cloud-native stack powered by enterprise-grade Nvidia H100 GPU infrastructure. The system runs 24/7 in the cloud, so users do not need to manage servers, colocate machines, or maintain exchange-side execution infrastructure themselves. In short, NeuralArB packages institutional-grade neural trading efficiency into a platform that can be accessed without building a private quant stack from scratch.
The x200 Growth Milestone: What Happened?
The NeuralArB x200 growth milestone was not achieved through a single model update. It was the result of a staged infrastructure program in which storage, data engineering, model design, and execution speed were expanded together. Each phase removed a different bottleneck, and each removed bottleneck exposed the next one. That compounding effect is what ultimately produced the current leap in neural trading efficiency.
Phase 1 (Q2-Q4 2024): Foundation.
In the earliest stage, available server-side data storage ranged from roughly 0.5 TB to 3.5 TB. That footprint was enough for basic spread detection, limited historical replay, and small-scale supervised model training. It was not enough for regime-aware learning. The system could observe recent behavior, but it could not yet compare a present-day dislocation to a deep catalog of prior market analogs.
Phase 2 (Q1-Q2 2025): First expansion.
Storage increased to 18 TB, and with that expansion came the practical integration of LSTM-based temporal modeling. This changed the bot from a primarily reactive engine into a system with stronger memory of sequence behavior. It could now analyze how spreads developed over time, how order books decayed before a move, and how liquidity migrated across venues over multiple intervals instead of isolated snapshots.
Phase 3 (Q3-Q4 2025): Transformer rollout.
Capacity scaled to 85 TB to support the attention heavy compute and storage requirements of Transformer models. This was a critical point in the story. The system gained more contextual intelligence, allowing it to connect signals across assets, exchanges, and timeframes. Macro news, volatility clusters, social sentiment shifts, and stablecoin flow changes could now be interpreted as part of a broader market state rather than as disconnected events.
Phase 4 (Q1-Q2 2026): Full 200 TB deployment.
With the full data lake online, the platform reached the operating scale required for the x200 milestone. The neural arbitrage bot could retrain hourly, backtest across multiple market cycles, and serve execution models with far deeper feature history. In effect, the storage layer stopped being a constraint and became a competitive weapon. That is the moment when server expansion arbitrage moved from infrastructure project to measurable performance edge.
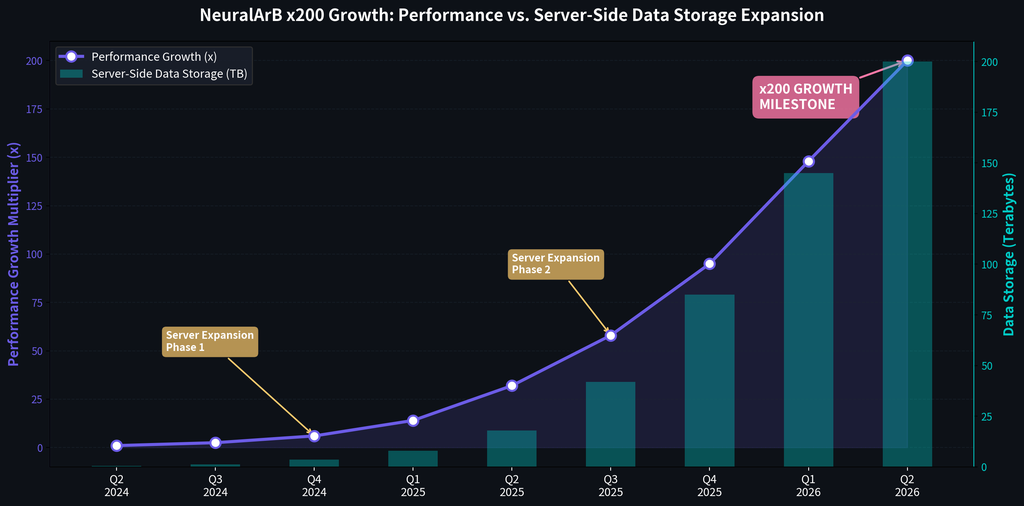
Server-Side Data Storage Expansion: The Catalyst
Server-side data storage was the critical catalyst because modern AI crypto arbitrage systems are only as strong as the evidence base they can learn from. In machine learning, more historical depth usually leads to better pattern recognition, but only if the data can be stored, indexed, retrieved, and replayed fast enough for model training and live decisioning. Before the expansion, storage limits forced trade-offs. We had to choose between shorter retention, lower feature richness, or slower retraining. None of those trade-offs scale well in high-frequency markets.
The new 200 TB architecture changed that equation. NeuralArB now operates on a true data lake that stores both structured and unstructured inputs. Structured data includes full-depth order books, tick-by-tick trades, funding rates, open interest, liquidation maps, fee schedules, and venue-specific latency statistics. Unstructured and semi-structured data includes sentiment streams, community chatter, event summaries, governance signals, and select on-chain telemetry. This breadth is important because profitable arbitrage often depends on context outside the last visible quote.
The difference between shallow data and deep data is operationally enormous. A 30-day dataset can teach a model how a recent volatility pocket behaved. It cannot teach the model how a stablecoin depeg, exchange outage, macro risk shock, post-halving rotation, or regulatory headline affected spread persistence across multiple venues years apart. With 3+ years of archived data, the neural arbitrage bot can compare current conditions against a much richer set of analogs. That improves ranking, not just detection.
Deep storage also enables more realistic backtesting. Instead of testing strategies in one favorable environment, NeuralArB can replay behavior across bull markets, bear markets, choppy range conditions, high-fee congestion periods, and cross-chain fragmentation phases. That matters because crypto arbitrage bot performance can look strong in one regime and collapse in another. Wider storage lets us stress-test the neural trading efficiency of the stack under multiple market personalities before a model reaches production.
On the engineering side, the data lake is paired with a high-throughput streaming pipeline and Nvidia H100 accelerators capable of sustaining up to 3 TB/sec of throughput for ingestion, feature construction, and model serving. Cloud-native storage was the logical choice because traditional on-premise deployments tend to introduce capacity ceilings, slower scaling cycles, and more painful maintenance windows. In contrast, our cloud-first approach reduces storage bottlenecks, supports distributed training, and allows the platform to keep pace with the expanding demands of server-side data storage at production scale.
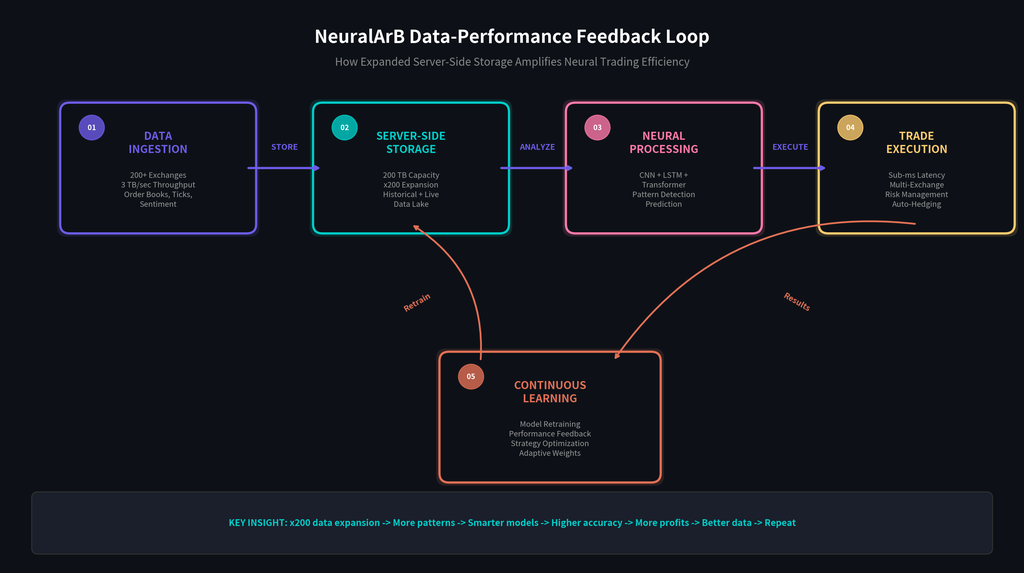
How Accumulated Data Increases Neural Trading Efficiency
Accumulated data improves neural trading efficiency because it gives each model family more examples, better context, and faster feedback. The most visible effect appears in pattern recognition at scale. NeuralArB’s CNN layers treat the order book like an image composed of price levels, queue depth, and liquidity gradients. With a shallow dataset, the model sees only a narrow slice of how these structures behave. With a 200 TB repository, it sees millions of examples of spoof like pressure, genuine absorption, thin book traps, and pre-breakout liquidity clustering across multiple venues and market regimes.
That additional visual training data makes the model far better at classifying whether a spread is tradable or merely visible. In arbitrage, that distinction is everything. A spread that appears profitable on paper can vanish if one side lacks depth, if fees are underestimated, or if venue response deteriorates during execution. More stored examples of those edge cases lead to better probability estimates and better suppression of false positives.
Temporal learning benefits just as much. LSTM networks are built to understand sequences rather than snapshots, and sequences in crypto are heavily path-dependent. A price gap created by a liquidation cascade behaves differently from a gap created by organic buying, and both differ from a gap caused by exchange specific latency. By training over 3+ years of history, the neural arbitrage bot learns repeatable patterns around seasonality, macro cycle transitions, funding distortions, regulatory headlines, and weekend liquidity decay. For more on adaptive learning in fast-moving markets, see our work on reinforcement learning in dynamic crypto markets.
Transformer-based contextual intelligence is where deep storage becomes especially powerful. Attention mechanisms do not just ask what happened; they ask what mattered relative to everything else. A richer archive produces richer attention maps. The system can learn that a burst in BTC perpetual volume on one venue, a stablecoin balance change on another, and a social-sentiment shift around a correlated altcoin often combine into a predictable short-lived mispricing. This is the kind of cross-venue, cross-asset reasoning that static bots cannot reproduce.
The expanded server-side data storage also changed the pace of model improvement. Before the upgrade, retraining was constrained by read/write overhead and data availability, so model refresh cycles were slower and more selective. Today, retraining can occur hourly instead of weekly. That tighter loop means more recent conditions are folded back into the production system faster. In other words, more data does not just improve the initial model; it shortens the time between market change and model adaptation.
Sentiment integration adds another layer of value. NeuralArB stores and processes large streams of X/Twitter, Reddit, Discord, and related community data to detect shifts in narrative intensity, engagement concentration, and signal propagation. Those features can be decisive when pricing diverges ahead of public order flow. We discussed this edge in detail in our article on NLP sentiment arbitrage. Storing this information natively in the data lake allows sentiment to be aligned with exchange, time, and asset level execution outcomes rather than treated as a detached dashboard metric.
Finally, accumulated data makes cross-chain analysis practical at production speed. The platform can track DeFi pool movements, centralized exchange books, bridge flows, and network congestion across Ethereum, L2 environments, and alternative chains at the same time. That creates a fuller map of where server expansion arbitrage opportunities are likely to emerge and how quickly they may decay. For more on that topic, see our overview of cross-chain MEV arbitrage opportunities. In short, accumulated data trading improves not one model output, but the entire decision chain from signal detection to execution ranking to post-trade learning.
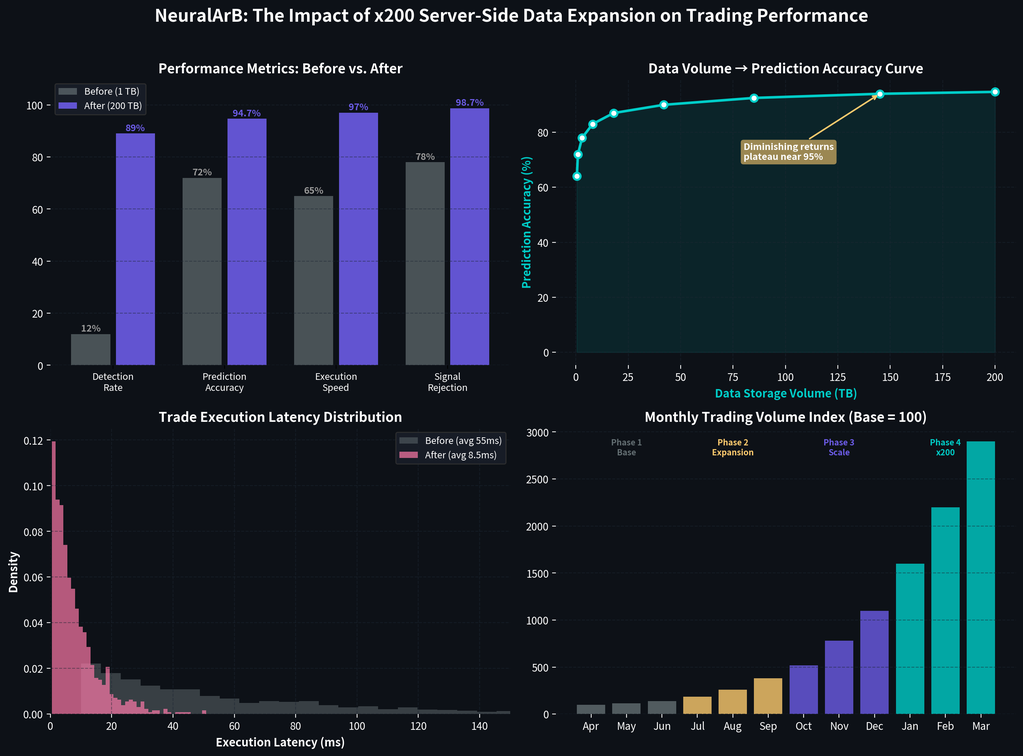
Before vs. After: Performance Metrics That Prove It
The impact of the infrastructure overhaul is best understood through measurable historical and simulated metrics. Expanding server-side data storage did not create a small incremental gain. It reshaped the platform’s opportunity surface, learning loop, and execution reliability. The table below compares the operating profile of the system when storage was constrained with the profile achieved after the 200 TB deployment.
Read the numbers together rather than in isolation. More storage allowed the system to monitor more exchanges, retrain more frequently, and rank trade quality more accurately. That combination increased arbitrage detection rate, improved false signal rejection, and reduced execution latency. The resulting lift in crypto arbitrage bot performance appears not only in raw opportunity volume but also in risk-adjusted statistics such as Sharpe ratio and drawdown control.
| Metric | Before (≤1 TB) | After (200 TB) | Improvement |
|---|---|---|---|
| Data Storage | 0.5-1 TB | 200 TB | x200 |
| Exchanges Monitored | 45 | 200+ | x4.4 |
| Prediction Accuracy | 72% | 94.7% | +31.5% |
| Arbitrage Detection Rate | 12/min | 89/min | x7.4 |
| Trade Execution Latency | 55ms | 8.5ms | -84.5% |
| False Signal Rejection | 78% | 98.7% | +26.5% |
| Risk-Adjusted ROI (90-day) | 43.9% | 415.3% | x9.5 |
| Sharpe Ratio | 1.2 | 3.8 | x3.2 |
| Max Drawdown | -8.7% | -2.4% | -72.4% |
These metrics highlight why data-driven trading is pulling away from older methodologies. Prediction accuracy rose to 94.7%, while trade execution latency dropped to 8.5 milliseconds. Just as important, the detection engine moved from spotting roughly 12 viable opportunities per minute to 89 per minute across a much wider venue set. That is a meaningful change in market coverage, not just a cosmetic uplift in a backtest headline. To see how those system improvements translated into practical execution behavior, explore our NeuralArB arbitrage case studies.
The most instructive figures may be the defensive ones. False signal rejection improved from 78% to 98.7%, and max drawdown narrowed from -8.7% to -2.4%. Those are the fingerprints of better filtering and better context, both of which come directly from richer training data and faster feedback loops. The rise in simulated 90-day risk-adjusted ROI from 43.9% to 415.3% should therefore be read as the outcome of an improved system design, not as a promise of future results. It also underscores the performance gap between enterprise grade neural infrastructure and basic tools, a gap we explored further in the truth about free arbitrage bots vs paid AI solutions.
Why Data Volume Is the #1 Factor in Neural Arbitrage
Data volume is the number one factor in neural arbitrage because deep learning systems improve as the diversity and depth of observations increase. In practice, the improvement curve is not linear forever. It tends to be steep in the early and middle stages, then gradually flattens as models approach very high accuracy levels. That is why moving from limited storage to 200 TB had such a dramatic effect:
NeuralArB was not adding redundant history; it was adding meaningful new examples at exactly the stage where more data still created outsized gains.
Traditional rule-based bots do not benefit in the same way. If a script only checks whether one price exceeds another after fees, ten years of history will not make that script more intelligent. It may help with manual tuning, but the logic itself does not learn. A neural arbitrage bot, by contrast, updates its internal representation of what a high-quality spread looks like, how long it should persist, and under which conditions execution risk is too high. That learning process depends directly on accumulated data.
Industry research on high-frequency trading and deep neural networks broadly supports the same conclusion:
more data plus more compute tends to produce better ranking, calibration, and robustness.
NeuralArB x200 growth matters because it moved the platform into a scale band where those effects became decisive. Server-side data storage is not a back-office utility here. It is the first-order input behind model quality and sustainable neural trading efficiency.
Real-World Impact: Case Studies
The practical value of deep storage is easiest to understand through concrete market scenarios. During the flash crash recovery of November 2025, the neural arbitrage bot recognized a sequence of order book thinning, forced selling, and spread widening that closely resembled a 2022 shock event stored in its historical archive. Because it could compare the live setup to a prior pattern rather than treating it as an unseen anomaly, the system was able to rank recovery-side opportunities more confidently while many simpler bots stayed defensive.
A second example came from cross-chain execution. With expanded storage, NeuralArB maintained simultaneous state on Ethereum L1, key Layer 2 environments, and Solana DEX venues, allowing it to track where pricing dislocations were opening and how quickly bridge or settlement friction might close them. That context made multi-leg routing more practical and helped surface the kind of opportunity profiles discussed in our analysis of cross-chain MEV arbitrage opportunities.
A third case involved sentiment-led arbitrage. By aligning stored social and community data with venue-level price response, NeuralArB flagged an XRP momentum shift 47 minutes before the move became obvious on major exchanges. That capability reflects the same principles covered in our discussion of NLP sentiment arbitrage. For readers who want a broader primer, our guide to crypto arbitrage 101 is a useful starting point, while the NeuralArB White Paper covers the deeper technical architecture.
NeuralArB’s Competitive Edge: What Sets It Apart
NeuralArB’s competitive edge starts with adaptivity. This is not a static spread-checking tool but an evolving neural arbitrage bot that refines itself as markets change. Because the platform sits on 200 TB of accumulated data, its models can be calibrated against a much broader set of historical precedents than most competitors can access.
The second differentiator is breadth. Monitoring 200+ exchanges and liquidity venues gives the system far more room to detect inefficiencies than a single-market or single-chain bot. That breadth is then converted into speed through Nvidia H100 acceleration, enabling low-latency inference and single-digit millisecond execution pathways.
The third differentiator is risk quality. A 98.7% false signal rejection rate, dynamic risk controls, insurance on deposits, and a user-friendly dashboard with API access combine institutional infrastructure with practical usability. The result is a platform built not just to find more trades, but to rank and filter them more intelligently.
The Future: What’s Next for NeuralArB
The NeuralArB x200 growth milestone is an important waypoint, not an endpoint. On the product side, the roadmap for Q2 2026 includes mobile app delivery and community features that make neural trading efficiency more accessible in a portable format. On the ecosystem side, Q4 2026 points toward token launch planning and deeper DeFi integration.
On the infrastructure side, the bigger story is continued scaling toward petabyte-class storage. As markets become more fragmented and data sources more heterogeneous, the value of server-side data storage will only increase. NeuralArB intends to keep compounding its advantage by expanding both the breadth of the data lake and the speed at which that data can be turned into execution intelligence.
💬 Frequently Asked Questions (FAQ)
What is NeuralArB and how does it work?
NeuralArB is an AI-powered crypto arbitrage platform. It uses deep learning models (CNN, LSTM, Transformer) to scan over 200 exchanges in real-time, detecting and automatically exploiting price discrepancies for risk-adjusted profits.
What does x200 growth mean for NeuralArB?
The x200 growth refers to the massive scaling of our server-side data storage from less than 1 TB to a 200 TB data lake. This expansion exponentially increased our bot’s performance, predictive accuracy, and data processing throughput.
How does server-side data storage improve neural trading?
More historical and real-time data allows our neural networks to recognize complex market patterns, learn from past market cycles, and refine their prediction accuracy, leading to a 98.7% false signal rejection rate.
What exchanges does NeuralArB support?
NeuralArB currently monitors and supports execution across more than 200 cryptocurrency exchanges simultaneously, including tier-one CEXs like Binance and Coinbase, as well as various cross-chain decentralized exchanges (DEXs).
How accurate is NeuralArB's arbitrage prediction?
Following the 200 TB data storage expansion, our simulated historical prediction accuracy improved significantly, jumping from 72% to an industry-leading 94.7%.
What neural network architectures does NeuralArB use?
We utilize a hybrid AI architecture that combines Convolutional Neural Networks (CNN) for order book liquidity mapping, Long Short-Term Memory (LSTM) for time-series trend analysis, and Transformers for contextual, cross-asset intelligence.
Is NeuralArB safe to use? What about risk management?
Yes. NeuralArB features dynamic risk management that adjusts position sizing based on real-time market volatility. Furthermore, the platform offers institutional-grade insurance on deposits to safeguard user capital.
How is NeuralArB different from free arbitrage bots?
Free bots are typically static, rule-based scripts that cannot adapt to market changes. NeuralArB is a dynamic, continuously learning AI engine powered by enterprise hardware, resulting in vastly superior execution speeds and risk-adjusted ROI.
What hardware does NeuralArB use for processing?
Our cloud-native infrastructure is powered by Nvidia H100 GPU accelerators, which allow the system to handle up to 3 TB/sec of data throughput with single-digit millisecond latency.
Can beginners use NeuralArB for crypto arbitrage?
Absolutely. Because the neural arbitrage bot operates entirely in the cloud 24/7 with an intuitive dashboard, users do not need to manage complex hardware or possess advanced coding skills to participate.
Ready to Leverage Accumulated Data Trading?
Disclaimer: These materials are for general information purposes only and are not investment advice or a recommendation or solicitation to buy, sell or hold any cryptoasset or to engage in any specific trading strategy. Some crypto products and markets are unregulated, and you may not be protected by government compensation and/or regulatory protection schemes. The unpredictable nature of the cryptoasset markets can lead to loss of funds. Tax may be payable on any return and/or on any increase in the value of your cryptoassets and you should seek independent advice on your taxation position.
Past performance, whether actual or indicated by historical or simulated tests of strategies, is no guarantee of future performance or success. All performance metrics cited regarding NeuralArB’s x200 growth and risk-adjusted ROI represent historical or simulated data.
