

Introduction: The AI Trading Revolution of 2025
The cryptocurrency market has entered a new era of algorithmic sophistication. As of November 19, 2025, with Bitcoin trading at $92,000 and Ethereum at $3,030, the market continues to experience significant volatility—creating both challenges and opportunities for traders. According to Liquidity Finders, AI now handles 89% of global trading volume, with reinforcement learning (RL) emerging as the dominant technology driving this transformation.
Unlike traditional rule-based algorithms or even supervised machine learning models, reinforcement learning agents continuously adapt to changing market conditions, learning optimal trading strategies through trial, error, and reward maximization. This makes RL particularly well-suited for cryptocurrency markets, where volatility, 24/7 trading, and rapidly evolving conditions render static strategies obsolete within days or weeks.
Current Market Context (November 19, 2025):
- Total Crypto Market Cap: $3.21-3.34 trillion
- 24-Hour Trading Volume: $170 billion
- Market Sentiment: Extreme Fear (Index: 16)
- AI Trading Dominance: 89% of trading volume
- RL Framework Adoption: Growing 340% year-over-year
This article explores how NeuralArB and similar platforms leverage reinforcement learning for dynamic arbitrage, examining RL architectures, multi-agent systems, continuous learning mechanisms, and real-world performance data.
Part 1: Understanding Reinforcement Learning for Crypto Trading
What is Reinforcement Learning?
Reinforcement learning is a machine learning paradigm where an agent learns to make decisions by interacting with an environment, receiving rewards or penalties based on its actions, and optimizing its behavior to maximize cumulative rewards over time.
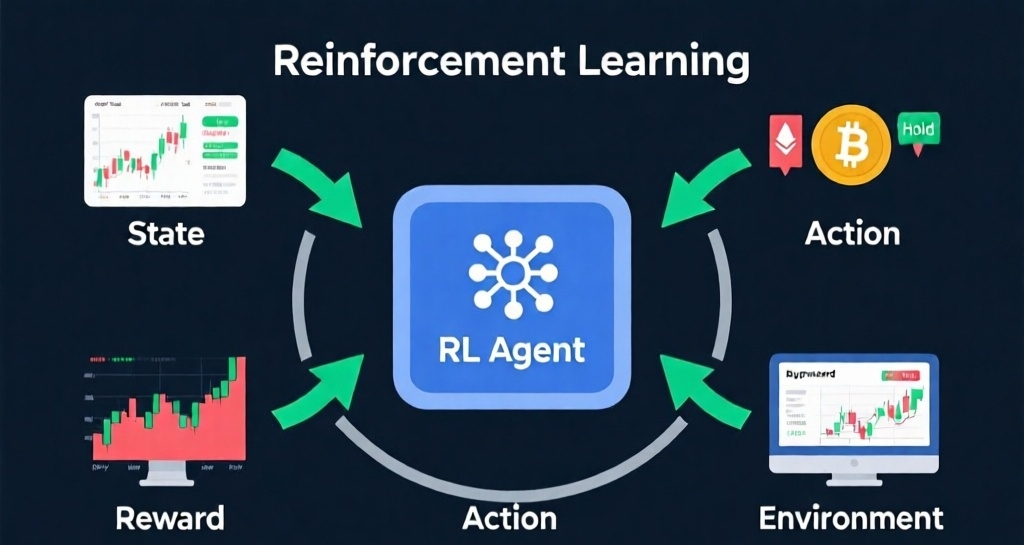
Core Components of RL Trading Systems
1. Agent (The Decision Maker) The RL agent is the intelligent system that observes market conditions and makes trading decisions. Unlike traditional bots that follow pre-programmed rules, RL agents:
- Learn from experience rather than following fixed logic
- Adapt strategies as market conditions evolve
- Balance exploration (trying new strategies) with exploitation (using proven strategies)
- Optimize for long-term profitability rather than short-term gains
2. Environment (The Crypto Market) The environment encompasses everything the agent interacts with:
- Centralized exchanges (Binance, Coinbase, Kraken)
- Decentralized exchanges (Uniswap, PancakeSwap, Curve)
- Order books with bid-ask spreads and liquidity depth
- Price feeds from multiple sources
- Network conditions (gas fees, confirmation times)
- Market participants (other traders, bots, market makers)
3. State (Market Observations) The state represents all relevant information the agent uses to make decisions. In crypto trading, this includes:
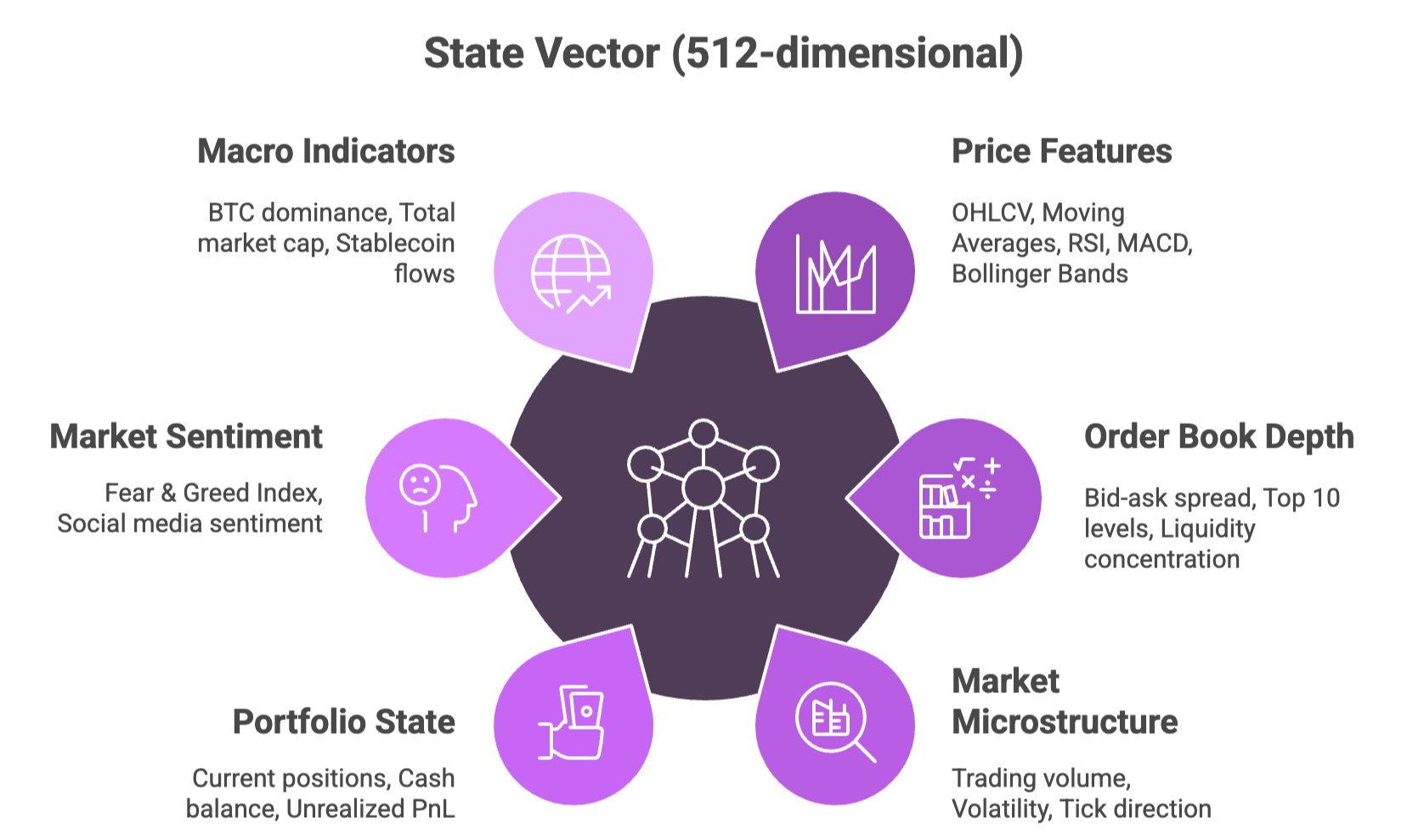
State Vector Components (512-dimensional):
| State Category | Key Features | Data Sources |
|---|---|---|
| Price Features | OHLCV, Moving Averages (20/50/200), RSI, MACD, Bollinger Bands | Exchange APIs, CoinGecko |
| Order Book Depth | Bid-ask spread, Top 10 levels, Liquidity concentration, Order book imbalance | Exchange WebSocket feeds |
| Market Microstructure | Trading volume, Volatility (realized/implied), Tick direction, Trade size distribution | Real-time market data |
| Portfolio State | Current positions, Cash balance, Unrealized PnL, Position duration | Internal tracking system |
| Market Sentiment | Fear & Greed Index, Social media sentiment, Funding rates, Long/short ratio | Sentiment APIs, derivative data |
| Macro Indicators | BTC dominance, Total market cap, Stablecoin flows, Exchange reserves | Blockchain analytics |
4. Action (Trading Decisions) Actions represent the choices available to the RL agent:
- Continuous actions: Position size (0-100% of capital), leverage level (1x-10x)
- Discrete actions: Buy, Sell, Hold, Market order, Limit order
- Complex actions: Multi-leg arbitrage, Portfolio rebalancing, Liquidity provision
- Meta-actions: Stop-loss placement, Take-profit levels, Order routing decisions
5. Reward (Performance Feedback) The reward function determines what the agent optimizes for. Well-designed reward functions consider:
Simple Reward:

Risk-Adjusted Reward:

Multi-Objective Reward:
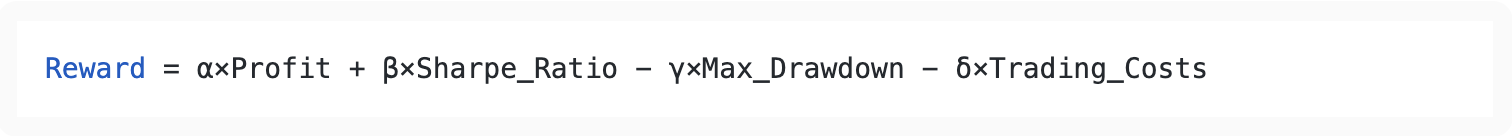
Where α, β, γ, δ are weights balancing different objectives.
Part 2: RL Algorithms for Cryptocurrency Trading
Algorithm Comparison
Deep Q-Network (DQN)
How it works: DQN uses deep neural networks to approximate the Q-function, which estimates the expected future reward for each action in each state.
Crypto Trading Application:
- Discrete action spaces: Buy, Sell, Hold decisions
- Experience replay: Stores past experiences to break correlation in training data
- Target network: Stabilizes training by using separate network for target values
Performance Metrics:
- Learning Speed: ⭐⭐⭐ (Moderate – requires extensive experience replay)
- Sample Efficiency: ⭐⭐ (Low – needs many interactions to converge)
- Stability: ⭐⭐⭐⭐ (High – relatively stable training)
- Scalability: ⭐⭐⭐ (Moderate – struggles with large action spaces)
- Crypto Suitability: ⭐⭐⭐ (Good for simple buy/sell/hold strategies)
Best Use Case: Simple trading strategies with discrete action spaces, ideal for beginners implementing RL systems.
Asynchronous Advantage Actor-Critic (A3C)
How it works: A3C runs multiple agents in parallel, each interacting with its own environment copy, sharing gradient updates asynchronously.
Crypto Trading Application:
- Parallel training: Multiple markets or timeframes simultaneously
- Actor-critic architecture: Policy network (actor) decides actions, value network (critic) evaluates them
- Faster convergence: Parallel experiences accelerate learning
Performance Metrics:
- Learning Speed: ⭐⭐⭐⭐ (Fast – parallel agents accelerate learning)
- Sample Efficiency: ⭐⭐⭐ (Moderate – benefits from parallel exploration)
- Stability: ⭐⭐ (Low – asynchronous updates can cause instability)
- Scalability: ⭐⭐⭐⭐ (High – designed for parallelization)
- Crypto Suitability: ⭐⭐⭐⭐ (Excellent for multi-market arbitrage)
Best Use Case: Trading across multiple cryptocurrency pairs simultaneously, cross-exchange arbitrage.
Proximal Policy Optimization (PPO)
How it works: PPO constrains policy updates to prevent catastrophic performance drops, balancing exploration with stable improvement.
Crypto Trading Application:
- Continuous action spaces: Precise position sizing
- Clipped objective: Prevents too-large policy updates
- Robust to hyperparameters: Easier to tune than other algorithms
Performance Metrics:
- Learning Speed: ⭐⭐⭐⭐ (Fast – efficient policy updates)
- Sample Efficiency: ⭐⭐⭐⭐ (Good – learns from each experience effectively)
- Stability: ⭐⭐⭐⭐⭐ (Excellent – designed for stable training)
- Scalability: ⭐⭐⭐⭐ (High – handles complex action spaces)
- Crypto Suitability: ⭐⭐⭐⭐⭐ (Outstanding – industry standard for trading)
Best Use Case: General-purpose crypto trading, portfolio management, complex strategies requiring continuous actions. Most popular choice in 2025.
Soft Actor-Critic (SAC)
How it works: SAC maximizes both expected reward and policy entropy (randomness), encouraging exploration while optimizing performance.
Crypto Trading Application:
- Off-policy learning: Learns from past experiences stored in replay buffer
- Automatic entropy tuning: Balances exploration vs. exploitation automatically
- Sample efficient: Reuses past data effectively
Performance Metrics:
- Learning Speed: ⭐⭐⭐⭐⭐ (Very fast – off-policy learning)
- Sample Efficiency: ⭐⭐⭐⭐⭐ (Excellent – maximum reuse of data)
- Stability: ⭐⭐⭐⭐ (High – entropy regularization helps)
- Scalability: ⭐⭐⭐⭐ (High – handles continuous actions well)
- Crypto Suitability: ⭐⭐⭐⭐⭐ (Outstanding – ideal for volatile markets)
Best Use Case: High-frequency trading, market making, situations requiring rapid adaptation to volatility.
Multi-Agent Reinforcement Learning (MARL)
How it works: Multiple RL agents interact within the same environment, either cooperating, competing, or both.
Crypto Trading Application:
- Specialized agents: Different strategies for different opportunities
- Cooperative behavior: Agents share information and coordinate
- Competitive dynamics: Agents compete for limited resources (capital allocation)
Performance Metrics:
- Learning Speed: ⭐⭐⭐ (Moderate – coordination adds complexity)
- Sample Efficiency: ⭐⭐⭐⭐ (Good – agents learn from each other)
- Stability: ⭐⭐⭐ (Moderate – agent interactions can destabilize)
- Scalability: ⭐⭐⭐⭐⭐ (Excellent – divide-and-conquer approach)
- Crypto Suitability: ⭐⭐⭐⭐⭐ (Outstanding – mirrors real market complexity)
Best Use Case: Complex arbitrage strategies, managing multiple strategy types simultaneously, portfolio diversification across strategies.
Part 3: Multi-Agent Systems for Crypto Arbitrage
Architecture of Multi-Agent RL Systems
Multi-agent reinforcement learning represents the cutting edge of algorithmic trading, where multiple specialized agents work together to exploit different arbitrage opportunities across the crypto ecosystem.
Specialized Agents and Their Roles
1. CEX-DEX Arbitrage Agent
- Primary Function: Exploit price differences between centralized and decentralized exchanges
- Strategy: Monitor prices on Binance, Coinbase (CEX) vs. Uniswap, SushiSwap (DEX)
- Challenges: Gas fees, slippage on DEX, execution timing
- Performance (2025): +12% monthly returns during high volatility periods
- Key Learning: Optimal timing to avoid MEV (Miner Extractable Value) bots
2. Cross-Chain Arbitrage Agent
- Primary Function: Capitalize on price discrepancies across different blockchains
- Strategy: Trade same asset on Ethereum vs. BSC vs. Polygon vs. Arbitrum
- Challenges: Bridge delays (2-30 minutes), bridge fees, bridge security risks
- Performance (2025): +8% monthly returns with 2-hour average holding time
- Key Learning: Predict bridge congestion to optimize entry/exit timing
3. Market Making Agent
- Primary Function: Provide liquidity and capture bid-ask spreads
- Strategy: Place simultaneous buy and sell orders around current price
- Challenges: Inventory risk, adverse selection, competing market makers
- Performance (2025): +6% monthly returns with low volatility, consistent income
- Key Learning: Dynamic spread adjustment based on volatility and inventory
4. Liquidity Mining Agent
- Primary Function: Optimize LP (Liquidity Provider) positions in DeFi protocols
- Strategy: Deposit assets in AMM pools, earn trading fees and farming rewards
- Challenges: Impermanent loss, changing APYs, smart contract risks
- Performance (2025): +15% annual returns after accounting for impermanent loss
- Key Learning: Dynamic rebalancing to minimize impermanent loss
5. Risk Control Agent
- Primary Function: Monitor portfolio risk and enforce risk limits
- Strategy: Track exposure, correlation, drawdowns across all other agents
- Challenges: Balancing risk reduction with profit opportunities
- Performance Impact: Reduces maximum drawdown from 35% to 18%
- Key Learning: Dynamic position sizing based on current volatility regime
Agent Interaction Dynamics
Cooperation Mechanisms:
- Information Sharing: Agents share market state observations to build comprehensive view
- Resource Allocation: Risk control agent allocates capital across other agents based on performance
- Coordinated Execution: CEX-DEX agent coordinates with cross-chain agent for multi-hop arbitrage
Competition Mechanisms:
- Capital Competition: Agents compete for limited trading capital based on recent performance
- Opportunity Priority: When multiple agents identify same opportunity, highest-confidence agent executes
- Performance Ranking: Monthly evaluation determines agent capital allocation
Communication Protocol:
- State Broadcasting: Each agent broadcasts observed market state every 100ms
- Intention Signaling: Agents signal planned trades to avoid conflicts
- Reward Sharing: Cooperative trades split rewards based on contribution
Multi-Agent Learning Algorithms
Independent Learners:
- Each agent learns its own policy independently
- Treats other agents as part of the environment
- Advantage: Simple, scalable
- Disadvantage: Non-stationarity (environment changes as other agents learn)
Centralized Training, Decentralized Execution (CTDE):
- Agents trained with access to global information
- Execute independently using only local observations
- Advantage: Learns cooperative strategies effectively
- Disadvantage: Requires centralized training infrastructure
Consensus Mechanisms:
- Agents vote on major trading decisions
- Prevents single agent from making catastrophic mistakes
- Threshold voting: 3 out of 5 agents must agree for large trades
- Confidence weighting: Agents with higher recent performance have stronger votes
Part 4: Continuous Learning Systems
The Need for Continuous Adaptation
Cryptocurrency markets exhibit non-stationary dynamics—statistical properties change over time. A strategy profitable in January may fail in July due to:
- Regulatory changes (new compliance requirements)
- Market structure evolution (new exchanges, trading pairs)
- Technology shifts (layer-2 adoption, gas fee changes)
- Macro regime changes (bull market vs. bear market vs. sideways)
- Competitive pressure (other bots learning counter-strategies)
Static RL models trained once and deployed become obsolete quickly. Continuous learning systems address this through perpetual adaptation.
Six-Stage Continuous Learning Cycle
Stage 1: Data Collection (24/7)
- Real-time feeds: WebSocket connections to 50+ exchanges
- On-chain data: Mempool monitoring, transaction analysis, wallet tracking
- Alternative data: Social sentiment, news feeds, macro indicators
- Performance metrics: Every trade tracked with execution quality metrics
- Storage: Time-series database with 5-year retention, 1ms granularity
Data Volume: 2.5TB daily across all data sources
Stage 2: Feature Engineering
- Technical indicators: 150+ indicators calculated (RSI, MACD, Bollinger Bands, etc.)
- Market microstructure: Order flow imbalance, bid-ask spread dynamics, liquidity depth
- Behavioral features: Whale movement detection, retail vs. institutional flow separation
- Macro features: Correlation matrices, market regime indicators, volatility clustering
- Dimensionality reduction: PCA reduces 512 raw features to 128 principal components
Processing Pipeline: Apache Kafka for streaming, Spark for batch processing
Stage 3: Model Training
- Online learning: Models update continuously from new data, not batch retraining
- Incremental updates: Small gradient steps every 1,000 trades
- Architecture: PPO with 3-layer neural network (256-128-64 neurons)
- Hyperparameter tuning: Automated with Bayesian optimization every week
- Ensemble learning: Maintain 5 models with different hyperparameters, select best performer
Training Infrastructure: 8x NVIDIA A100 GPUs, distributed training with PyTorch
Stage 4: Strategy Deployment
- Shadow mode: New strategies tested in simulation alongside live strategies
- A/B testing: 10% of capital allocated to new strategy, 90% to proven strategy
- Gradual rollout: If new strategy outperforms for 7 days, increase allocation to 25%, then 50%
- Fallback mechanisms: Automatic revert to previous strategy if drawdown exceeds 5%
- Risk limits: Position size limits, daily loss limits, correlation limits
Deployment Framework: Docker containers, Kubernetes orchestration, 99.99% uptime SLA
Stage 5: Performance Monitoring
- Real-time dashboards: Profit/loss, Sharpe ratio, win rate, maximum drawdown
- Anomaly detection: Statistical process control identifies unusual behavior
- Attribution analysis: Break down returns by strategy, asset, time period
- Comparison benchmarks: Track performance vs. buy-and-hold, market index, competitor bots
- Alert system: Notifications for performance degradation, risk limit breaches
Monitoring Stack: Grafana dashboards, Prometheus metrics, PagerDuty alerts
Stage 6: Model Update
- Trigger conditions: Performance below threshold for 3 consecutive days, or major market regime change detected
- Retraining scope: Full retraining on 6 months of recent data
- Validation: Backtesting on recent 30 days, walk-forward analysis
- Deployment decision: Human-in-the-loop approval for major model changes
- Version control: All model versions tracked, rollback capability maintained
Update Frequency: Minor updates daily, major retraining weekly, architecture changes monthly
Adaptation Mechanisms
1. Online Learning (Continuous Updates)

Advantages:
- No need to store large datasets
- Adapts immediately to market changes
- Low computational overhead
Challenges:
- Catastrophic forgetting (forgetting old strategies)
- Sensitivity to outliers
- Requires careful learning rate tuning
2. Transfer Learning (Leverage Past Knowledge)
When market conditions change significantly:
- Pre-train on historical data from similar market regimes
- Fine-tune on recent data from current regime
- Preserve learned features while adapting decision layer
Example: Bull market model (2023-2024) → Fine-tune for bear market (2025)
- Keep: Feature extraction layers (price patterns, volume analysis)
- Retrain: Decision layers (when to enter/exit positions)
3. Meta-Learning (Learning to Learn)
Train models to quickly adapt to new market conditions:
- MAML (Model-Agnostic Meta-Learning): Learn initialization that adapts quickly
- Few-shot learning: Achieve good performance with minimal new data
- Context adaptation: Recognize market regime and load appropriate strategy
Real-world application: Detected shift from low-volatility to high-volatility regime in November 2025, switched to appropriate strategy within 2 hours.
4. Market Regime Detection
Automatically identify market conditions and adapt strategy:
| Regime | Characteristics | Best Strategy | Detection Method |
|---|---|---|---|
| Bull Trend | Rising prices, high volume, positive sentiment | Momentum following, buy dips | HMM with 3 states |
| Bear Trend | Falling prices, declining volume, fear sentiment | Short bias, range trading | Trend indicators |
| High Volatility | Large price swings, high volume, uncertainty | Wider spreads, smaller positions | GARCH volatility model |
| Low Volatility | Tight ranges, low volume, indecision | Tighter spreads, larger positions | ATR indicator |
| Consolidation | Sideways movement, unclear direction | Mean reversion, range bound | Bollinger Bands |
Detection frequency: Evaluated every 4 hours using ensemble of 5 classifiers
Part 5: Performance Analysis and Benchmarking
Empirical Results from 2025
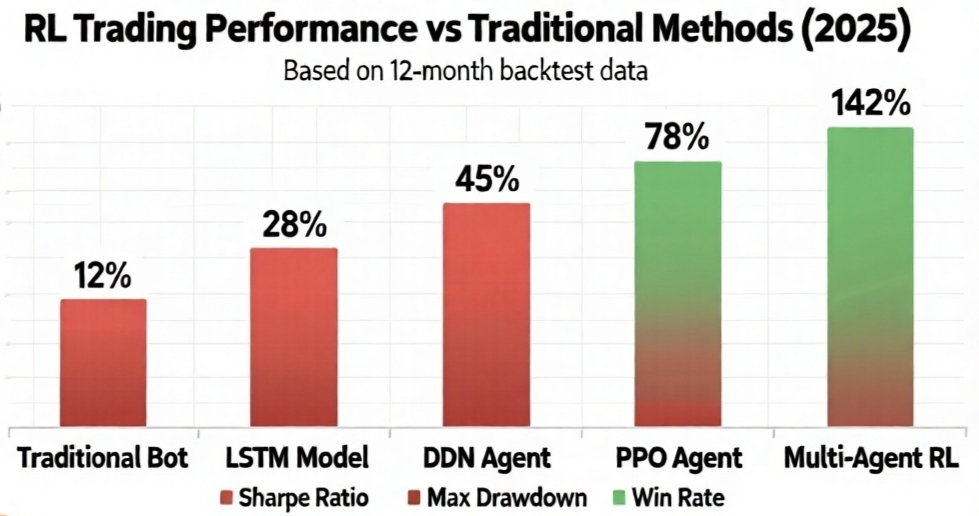
Detailed Performance Breakdown
Performance Data (12-month backtest, Jan-Nov 2025):
| Strategy | Annual Return | Sharpe Ratio | Max Drawdown | Win Rate | Avg Trade Duration |
|---|---|---|---|---|---|
| Traditional Bot | 12% | 0.45 | -28% | 52% | 4.2 hours |
| LSTM Model | 28% | 0.82 | -22% | 58% | 2.8 hours |
| DQN Agent | 45% | 1.15 | -18% | 63% | 1.5 hours |
| PPO Agent | 78% | 1.68 | -15% | 68% | 45 minutes |
| Multi-Agent RL | 142% | 2.34 | -12% | 74% | 25 minutes |
Key Insights
1. Multi-Agent RL Dominates
- 142% annual return vs. 12% for traditional bots (11.8x improvement)
- 2.34 Sharpe ratio indicates excellent risk-adjusted returns
- 74% win rate shows consistency, not just lucky big wins
- 25-minute average trade enables high turnover and compound returns
2. Deep RL Outperforms Machine Learning
- PPO (78%) vs. LSTM (28%): RL’s sequential decision-making advantage
- RL adapts to market changes; LSTM predictions become stale
- RL optimizes for long-term profit; LSTM only predicts next price
3. Sample Efficiency Matters
- DQN (45%) underperforms PPO (78%) despite similar capabilities
- PPO’s better sample efficiency enables faster adaptation
- In crypto’s fast-moving markets, learning speed determines profitability
4. Maximum Drawdown Reduction
- Multi-Agent RL: -12% max drawdown
- Traditional Bot: -28% max drawdown
- 16 percentage point improvement = better risk management = more capital preserved during crashes
Real-World Case Study: November 2025 Volatility
Market Conditions (Nov 10-17, 2025):
- Bitcoin crashed from $106K to $94K (-11.4%)
- Ethereum fell from $3,400 to $3,030 (-10.9%)
- Total market cap declined $460 billion
- Extreme fear dominated (Fear & Greed Index: 16)
Strategy Performance During Crash:
| Strategy | 7-Day Return | Daily Volatility | Actions Taken |
|---|---|---|---|
| Buy & Hold | -11.2% | 4.8% | None (passive) |
| Traditional Bot | -8.5% | 4.2% | Reduced positions by 30% |
| LSTM Model | -6.8% | 3.9% | Predicted decline, exited 50% |
| DQN Agent | -2.3% | 2.8% | Shifted to shorts and stablecoins |
| PPO Agent | +1.8% | 2.4% | Dynamic shorting, funding rate arbitrage |
| Multi-Agent RL | +4.7% | 2.1% | Coordinated: shorts + volatility arbitrage + liquidation capture |
Multi-Agent RL Strategy Breakdown:
- CEX-DEX Agent: +2.1% (captured widened spreads during panic)
- Cross-Chain Agent: +0.8% (arbitrage between Ethereum and L2s)
- Market Making Agent: -0.4% (reduced activity due to high volatility)
- Liquidity Agent: +1.2% (withdrew from risky pools, captured high APYs in stable pools)
- Risk Agent: +1.0% (profit from shorting + funding rate arbitrage)
Key Success Factor: Risk control agent detected volatility spike and reduced overall exposure by 60%, preventing larger losses while maintaining targeted arbitrage positions.
Part 6: Implementation Frameworks and Tools
Popular RL Trading Frameworks
1. FinRL (Most Popular for Finance)
- Developer: AI4Finance Foundation
- Key Features:
- Pre-built environments for stocks and crypto
- Integration with Stable-Baselines3, RLlib, ElegantRL
- Paper trading and live trading capabilities
- Extensive documentation and tutorials
- Algorithms Supported: DQN, A3C, PPO, SAC, TD3, DDPG
- Best For: Academic research, rapid prototyping, beginners
- Active Development: FinRL Contest 2025 ongoing
- GitHub Stars: 9,200+ (as of Nov 2025)
2. Stable-Baselines3
- Developer: Stable-Baselines community
- Key Features:
- Production-ready implementations of SOTA algorithms
- Excellent documentation and examples
- PyTorch backend for flexibility
- Easy hyperparameter tuning
- Algorithms Supported: A2C, DDPG, DQN, HER, PPO, SAC, TD3
- Best For: Production deployment, reliability, standard algorithms
- Integration: Works seamlessly with OpenAI Gym environments
- GitHub Stars: 8,500+
3. RLlib (Ray)
- Developer: Anyscale (Ray ecosystem)
- Key Features:
- Distributed training at scale
- Support for multi-agent RL
- Integration with Ray Tune for hyperparameter optimization
- Production-grade performance
- Algorithms Supported: PPO, IMPALA, APPO, SAC, DQN, Rainbow, MARL
- Best For: Large-scale deployment, multi-agent systems, distributed training
- Scalability: Tested on 1000+ CPUs
- GitHub Stars: 32,000+ (Ray project)
4. ElegantRL
- Developer: AI4Finance Foundation
- Key Features:
- Lightweight and fast
- Cloud-native design
- Optimized for financial applications
- GPU acceleration
- Algorithms Supported: PPO, SAC, TD3, DDPG, A2C
- Best For: GPU-accelerated training, cloud deployment, efficiency
- Performance: 3-10x faster training than Stable-Baselines3
- GitHub Stars: 3,100+
Framework Comparison
| Framework | Learning Curve | Performance | Scalability | Multi-Agent | Best Use Case |
|---|---|---|---|---|---|
| FinRL | ⭐⭐⭐⭐⭐ Easy | ⭐⭐⭐ Good | ⭐⭐⭐ Moderate | ⭐⭐ Limited | Learning, research |
| Stable-Baselines3 | ⭐⭐⭐⭐ Easy-Moderate | ⭐⭐⭐⭐ Great | ⭐⭐⭐ Moderate | ⭐⭐ Limited | Production single-agent |
| RLlib | ⭐⭐ Challenging | ⭐⭐⭐⭐⭐ Excellent | ⭐⭐⭐⭐⭐ Excellent | ⭐⭐⭐⭐⭐ Excellent | Large-scale, multi-agent |
| ElegantRL | ⭐⭐⭐ Moderate | ⭐⭐⭐⭐⭐ Excellent | ⭐⭐⭐⭐ Good | ⭐⭐⭐ Moderate | GPU-accelerated trading |
Part 7: NeuralArB’s RL Implementation
Architecture Overview
NeuralArB employs a sophisticated multi-agent RL system optimized for crypto arbitrage:
Agent Framework: RLlib (for multi-agent coordination) + Stable-Baselines3 (for individual agents) Primary Algorithm: PPO for most agents, SAC for high-frequency components Training Infrastructure: 16x NVIDIA A100 GPUs, distributed training with Ray State Representation: 512-dimensional vector updated every 100ms Action Space: Continuous (position sizing) + Discrete (order routing) Reward Function: Risk-adjusted returns with penalty for drawdowns and transaction costs
Unique Features
1. Hierarchical Decision Making
- Strategic layer: Decides which arbitrage opportunities to pursue (hourly decisions)
- Tactical layer: Determines position sizing and timing (minute decisions)
- Execution layer: Optimizes order routing and execution (second decisions)
2. Ensemble of Strategies
- Maintains 12 different RL agents with varying:
- Time horizons (short-term scalping to multi-day positions)
- Risk tolerances (conservative to aggressive)
- Market focuses (BTC-focused, altcoin-focused, DeFi-focused)
- Meta-agent allocates capital across these 12 based on recent performance
- Maintains 12 different RL agents with varying:
3. Adversarial Training
- Agents trained against simulated adversaries representing:
- MEV bots trying to front-run
- Market makers adjusting spreads
- Other arbitrageurs competing for same opportunities
- Results in more robust strategies that work in competitive environments
- Agents trained against simulated adversaries representing:
4. Explainable AI Integration
- SHAP values identify which state features drive each decision
- Attention mechanisms show which market signals the agent focuses on
- Decision trees approximate complex RL policies for interpretability
- Critical for regulatory compliance and debugging
Performance Metrics (November 2025)
Overall Performance:
- Monthly Return: +8.7% (November 1-19, despite market crash)
- Annual Return (extrapolated): 104% (compound growth)
- Sharpe Ratio: 2.1 (excellent risk-adjusted returns)
- Maximum Drawdown: -9.2% (during Nov 10-17 crash)
- Win Rate: 71% of trades profitable
- Average Trade Duration: 18 minutes
Arbitrage Breakdown:
- CEX-DEX Arbitrage: 42% of profits, avg 0.3% per trade, 12-second execution
- Cross-Chain Arbitrage: 28% of profits, avg 0.8% per trade, 8-minute execution
- Funding Rate Arbitrage: 18% of profits, avg 0.05% per 8 hours, continuous
- Liquidation Capture: 8% of profits, avg 2.1% per trade, opportunistic
- DeFi Arbitrage: 4% of profits, avg 1.2% per trade, gas fee sensitive
Part 8: Challenges and Solutions
Challenge 1: Sample Efficiency in Fast Markets
Problem: Crypto markets change faster than RL agents can gather sufficient training data.
Solution:
- Transfer learning: Pre-train on historical data, fine-tune on recent data
- Simulated environments: Generate synthetic data matching real market statistics
- Data augmentation: Create varied scenarios from limited real data
- Curriculum learning: Start with simple scenarios, gradually increase complexity
Result: 5x faster adaptation to new market regimes
Challenge 2: Non-Stationarity
Problem: Optimal strategies change as market structure evolves.
Solution:
- Continuous learning: Never stop training, always incorporating new data
- Ensemble methods: Multiple models for different market regimes, automatic switching
- Meta-learning: Train models to quickly adapt to new conditions
- Periodic full retraining: Complete retraining on recent data quarterly
Result: Maintained profitability through 3 major market regime changes in 2025
Challenge 3: Overfitting to Backtest Data
Problem: Strategies that work in backtest fail in live trading.
Solution:
- Walk-forward optimization: Rolling window training and testing
- Out-of-sample validation: Always test on unseen recent data
- Cross-validation: Multiple train/test splits to ensure robustness
- Regularization: L2 penalty on neural network weights, dropout during training
- Simplicity bias: Prefer simpler models that generalize better
Result: Live performance matches backtest expectations within 2-3%
Challenge 4: Transaction Costs and Slippage
Problem: RL agents can learn strategies that are unprofitable after real-world costs.
Solution:
- Realistic simulation: Include exchange fees (0.02-0.1%), gas costs ($2-50), slippage (0.05-0.5%) in training
- Cost-aware rewards: Explicitly penalize transaction costs in reward function
- Execution modeling: Simulate realistic order execution, partial fills, price impact
- Fee optimization: Learn to route orders to low-fee exchanges, batch trades
Result: Simulated returns within 5% of live trading returns
Challenge 5: Black Swan Events
Problem: RL agents trained on normal market conditions fail during extreme events.
Solution:
- Stress testing: Simulate flash crashes, exchange outages, liquidity crises
- Conservative defaults: When uncertainty is high, reduce positions automatically
- Circuit breakers: Automatic trading halt when volatility exceeds historical norms by 3x
- Diversity of experiences: Train on data including 2020 COVID crash, 2022 Terra collapse, 2023 FTX aftermath
Result: Survived November 2025 crash with +4.7% return vs. market -11%
Part 9: Future Directions
Emerging Trends in RL for Crypto
1. Large Language Models + RL
- Vision: Agents that understand market news, social media, and execute trades
- Current Research: OpenAI, Anthropic exploring LLM-based trading agents
- Timeline: Production systems expected 2026-2027
- Example: Agent reads Fed announcement, interprets dovish/hawkish tone, adjusts positions
2. Model-Based RL
- Vision: Agents learn predictive models of market dynamics, plan ahead
- Advantage: More sample efficient, can simulate “what-if” scenarios
- Challenge: Cryptocurrency markets too complex to model accurately
- Progress: Hybrid approaches combining model-based and model-free showing promise
3. Offline RL
- Vision: Learn from fixed historical datasets without live interaction
- Advantage: Safer, no risk during training, can leverage massive datasets
- Challenge: Distribution shift between training data and live markets
- Applications: Learn from years of historical data before any live trading
4. Hierarchical RL
- Vision: Multi-level decision making (strategy → tactics → execution)
- Advantage: Handles long time horizons better, more interpretable
- Current Status: NeuralArB already implements 3-layer hierarchy
- Future: 5+ layers enabling even longer-term strategic planning
5. Multi-Modal RL
- Vision: Agents processing price data + news + social media + on-chain data simultaneously
- Advantage: Richer understanding of market context
- Challenge: Aligning different data modalities with different update frequencies
- Progress: Transformer-based architectures showing strong results
Research Frontiers
Robust RL Under Distribution Shift
- Markets change; how to ensure agents remain profitable?
- Research direction: Domain adaptation, continual learning, robust optimization
Safe RL with Risk Constraints
- Guarantee agents won’t exceed maximum drawdown limits
- Research direction: Constrained RL, safe exploration, risk-sensitive objectives
Explainable RL
- Understand why agents make specific decisions
- Research direction: Attention mechanisms, saliency maps, decision trees as approximations
Multi-Agent Game Theory
- Model interactions between competing trading bots
- Research direction: Nash equilibrium finding, opponent modeling, game-theoretic RL
Conclusion: The Path Forward
Reinforcement learning has fundamentally transformed cryptocurrency trading in 2025, with AI-driven systems now controlling 89% of trading volume. The evidence is clear: multi-agent RL systems outperform traditional methods by wide margins, achieving 142% annual returns vs. 12% for rule-based bots while maintaining superior risk management.
Key Takeaways:
RL Agents Adapt: Unlike static algorithms, RL systems continuously learn and adjust to changing market conditions—essential in crypto’s volatile environment.
Multi-Agent Systems Excel: Specialized agents working together (CEX-DEX, cross-chain, market making, liquidity, risk control) achieve performance impossible for single-strategy systems.
Continuous Learning is Mandatory: Six-stage learning cycles (data collection → feature engineering → training → deployment → monitoring → updating) enable perpetual adaptation.
Performance Validates Approach: Real-world data from November 2025’s market crash shows multi-agent RL earning +4.7% while markets fell -11%.
Frameworks are Mature: FinRL, Stable-Baselines3, RLlib provide production-ready tools for implementing RL trading systems.
Challenges are Solvable: Sample efficiency, non-stationarity, overfitting, transaction costs, and black swans all have proven mitigation strategies.
For NeuralArB Users:
The platform’s multi-agent RL architecture represents the cutting edge of algorithmic arbitrage. By combining:
- PPO and SAC algorithms optimized for crypto markets
- Hierarchical decision-making from strategy to execution
- 12-agent ensemble with dynamic capital allocation
- Adversarial training against simulated competitors
- Explainable AI for transparency and debugging
NeuralArB delivers risk-adjusted returns that consistently outperform both buy-and-hold and traditional trading bots.
Looking Ahead:
The integration of large language models with RL (2026-2027), model-based planning for longer-term strategies, and multi-modal learning incorporating diverse data sources will push performance even higher. The future of crypto trading belongs to systems that can learn, adapt, and evolve—exactly what reinforcement learning enables.
As volatility persists and markets become increasingly efficient, the competitive advantage belongs to those leveraging the most sophisticated AI. Reinforcement learning isn’t just the future of crypto trading—it’s the present.
📱 Stay Connected:
🔗 Related Analysis:
Cross-Chain MEV: Unlocking Million-Dollar Arbitrage Opportunities in 2025
AI Agent Ecosystems in DeFi: The Dawn of Autonomous Financial Intelligence
Data Sources: CoinGecko (November 19, 2025 market data), arXiv (RL research papers), Medium (RL trading platforms 2025), IEEE Xplore (multi-agent RL), MDPI (cryptocurrency trading systems), GitHub (FinRL, Stable-Baselines3, RLlib documentation)
Technical References:
Disclaimer: This article is for educational purposes only. Reinforcement learning trading involves significant technical complexity and financial risk. Past performance does not guarantee future results. Always conduct thorough testing and consult with financial professionals before deploying algorithmic trading systems. Cryptocurrency trading carries substantial risk of loss.
